upLIFTをわかりやすくご紹介!


upLIFTをわかりやすくご紹介!
皆さんは「upLIFT」という翻訳メモリの機能を聞いたことはありますか?
聞いたことはあるけど実際に使ったことはない、という方も多いかもしれません。
今日はupLIFTについてわかりやすくご紹介しますので、Trados Studio 2017以降をお使いの方はぜひご利用ください。今までよりも多くの候補を翻訳メモリから取得することができますよ!
【upLIFTとは】
~upLIFTを使うと、今までよりも多くの候補を翻訳メモリから検索することができます。~
upLIFTはTrados Studio 2017(日本語は2017 SR1)から追加された翻訳メモリの新しい技術です。
今まで翻訳メモリは分節単位での検索しか行うことができませんでしたが、upLIFTを活用すると分節全体だけでなく、分節の前半/句/単語のような分節の一部も認識できます。(技術的には構文解析という解析が行われています)
※本ブログ内で使われる「フラグメント」という言葉は「文をさらに分解した句/単語」のことを意味しています。
新しい機能
これにより以下の2つの機能が使えるようになりました。
①フラグメント一致
フラグメント一致は分節の一部を検索する機能です。
以下の例の場合、7分節目には分節単位の一致候補はありませんが「source and target languages」という句に対し部分的なマッチ「ソースとターゲットの言語」や「ソース言語とターゲット言語」などが表示されています。
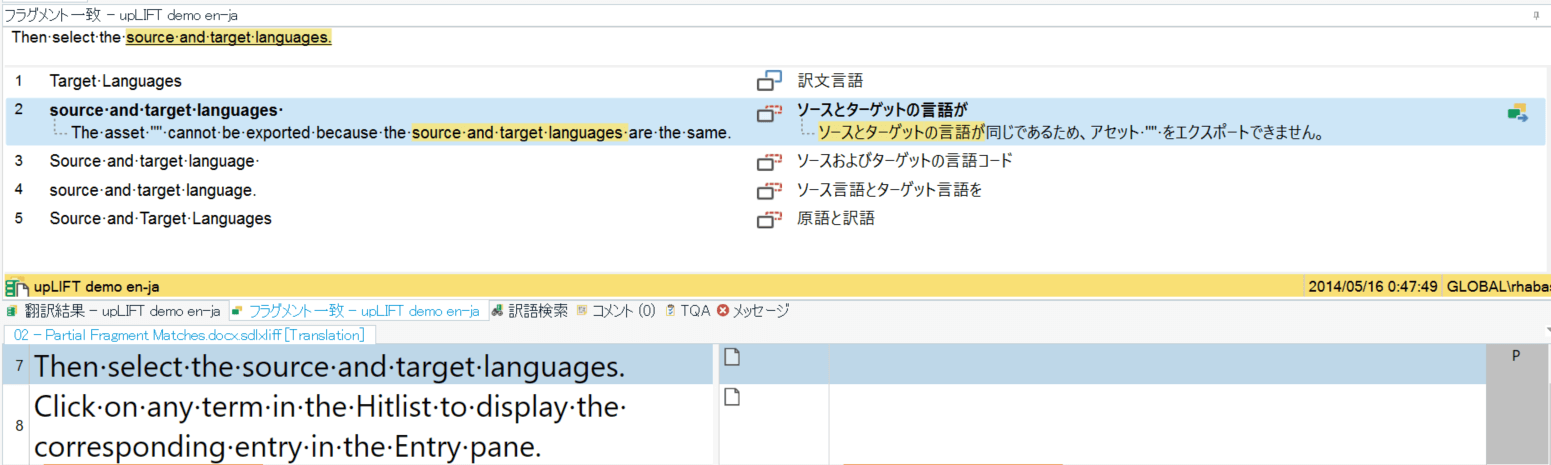
ここで何が起きているかというと、「source and target languages」を含む別の分節が翻訳メモリに既に登録されているのでそこから候補を部分的に持ってきているんです。
フラグメント一致を使用しないと、候補は何もありませんので「source and target languages」を含む1分節全体を手で翻訳する必要があります。「source and target languages」は訳したことがあるので部分的にでも再利用できれば嬉しいですよね。
尚、翻訳メモリの結果ウィンドウは下のタブでフラグメント一致や訳語検索(コンコーダンス検索)結果やコメントに表示が切り替わるデザインになっています。
1番左のタブには分節単位の候補(通常の翻訳メモリの検索結果)が表示され、その右のタブにはフラグメント一致の候補が表示されます。
分節単位の候補があれば優先して [翻訳結果] タブに訳文候補が自動で表示され、分節単位の候補はないが部分的にマッチがある場合は [フラグメント一致] タブに自動で切り替わり部分的な訳文候補が表示される仕組みになっています。
また、以下のように分節全体が短い翻訳単位が翻訳メモリに登録されている場合は、
この分節全体がフラグメントとしても機能します。
②あいまい一致の修正
2つ目は「あいまい一致」の修正です。
たとえば、翻訳メモリから90%マッチの類似が見つかった場合、従来は手動で10%の差分を修正する必要がありました。
upLIFTの「あいまい一致の修正」機能を使うと、差分をTradosが自動で修正してくれるので手動で修正する手間を軽減できます。
以下は、6番目の分節に87%のあいまい一致が見つかった例です。ここで差分は「translation memory」と「termbase」ですので、本来は訳文候補を挿入し「翻訳メモリ→用語ベース」に手動で修正する必要があります。
「あいまい一致の修正」を利用すると、「翻訳メモリ→用語ベース」に修正済みの状態で訳文候補が表示されますので、この候補を挿入するだけでこの分節の翻訳を完了できます。

あいまい一致の自動修正が適用された分節には、マッチ率(87%)の隣に工具のレンチマークがつくので簡単に判別ができます。自動修正を使用せずに翻訳をすることも可能です。
どうしてTradosが自動で修正を行えるかというと、以下3つのリソースから修正データを持ってこられるからなんです。
- 翻訳メモリのフラグメント
- 用語ベース
- 機械翻訳(接続している場合)
上記の例では用語ベースに[termbase:用語ベース]というペアが登録されていたか、[termbase:用語ベース]を含む分節が翻訳メモリに登録されていたため、「用語ベース」という訳語を自動で挿入できたんですね。この原理わかりますか?
とても便利な機能ですので頑張って理解してくださいね。
メモ:
あいまい一致の自動修正が働くためには、プロジェクトに設定されている翻訳メモリに翻訳単位(原文分節と訳文分節のペア)が少なくとも1,000件(推奨は5,000件以上)登録されている必要があります。
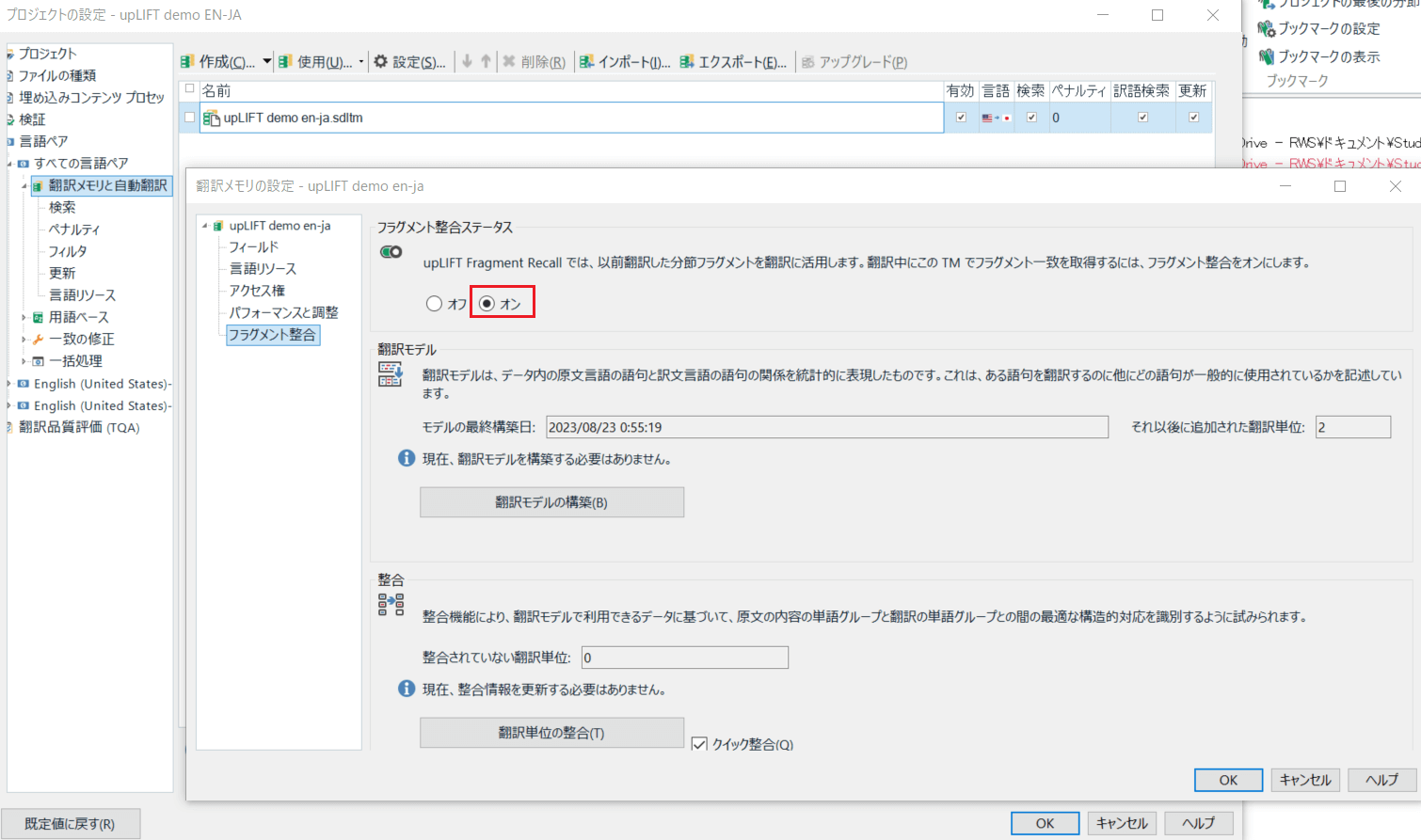
プロジェクトに設定した翻訳メモリがこの条件を満たしているかどうかを確認するには、[プロジェクトの設定] > [言語ペア] > [すべての言語ペア] > [翻訳メモリと自動翻訳] で(翻訳メモリ名の左にあるチェックボックスは選択せずに)翻訳メモリの名前をクリックし、その上の [設定] ボタン(歯車のアイコンの付いたボタン)をクリックします。
その後、[翻訳メモリの設定] ダイアログボックスの左側で [フラグメント整合] を選択し、[フラグメント整合ステータス] の下にあるラジオボタンが [オン] になっているかどうかを確認します(あいまい一致の自動修正が働くための条件が満たされている場合は、自動的に [オン] が選択されていますが、条件を満たしていない場合は [オフ] が選択されており、[オン] に切り替えることはできません)。
また、既定では、あいまい一致の自動修正はエディタで各分節にカーソルを置いたときにだけ働きますが、プロジェクトの作成時などに文書の「一括翻訳」を実行する際に、翻訳メモリからあいまい一致もあらかじめ分節に適用しておく設定にし、なおかつあいまい一致の自動修正が適用された訳文をあらかじめ訳文分節に適用することもできます。
これを行うための設定手順は以下のとおりです。
1. 一括翻訳を実行する際にあらかじめ自動修正が適用されたあいまい一致を訳文分節に適用しておきたい場合は、[ファイル] > [オプション] > [言語ペア] > [すべての言語ペア] > [翻訳メモリと自動翻訳] > [一致の修正] で、[一括タスク] の横にあるラジオボタンを [オフ] から [オン] に切り替えます。
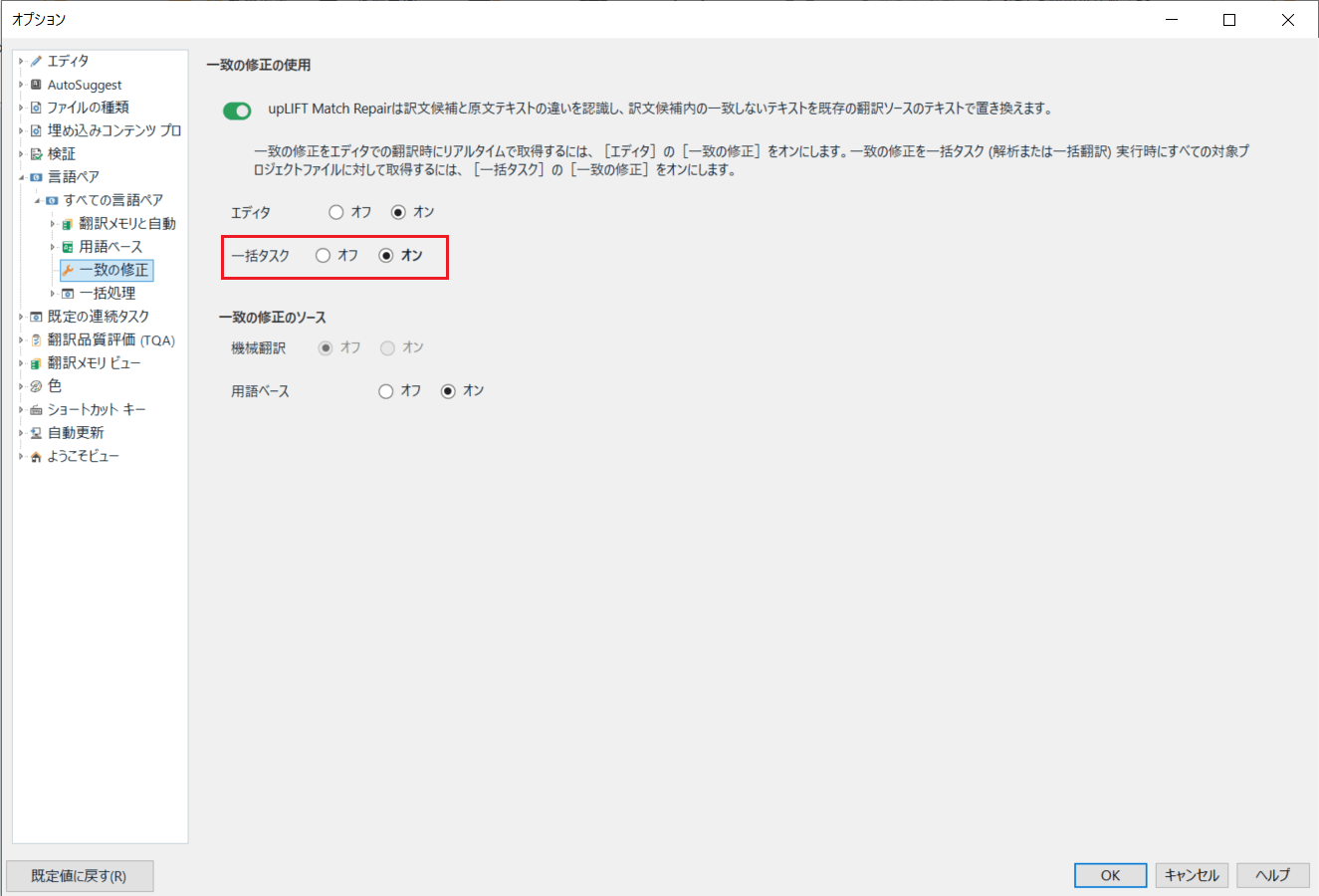
※ [ファイル] > [オプション] で行った設定変更は、以後に同じTrados Studio環境で作成されるすべてのプロジェクトに適用されます。プロジェクトの作成時にこの設定を適用したくない場合は、[一括タスク] の横のラジオボタンを[オフ] に切り替えてからプロジェクトの作成を開始してください。
2. [新しいプロジェクトの作成] ウィザードを開始し、ステップ7 [一括タスク] ページの左ペインで [すべての言語ペア] > [一括処理] > [一括翻訳] を選択して、右側にある [一括翻訳の設定] の下の [一致率の最小値] を99~70%の間に設定してからプロジェクトの作成を実行します。
※ 作成済みのプロジェクトに含まれるバイリンガルファイルに対して後から一括翻訳を実行したい場合は、[ファイル] ビューで対象となるバイリンガルファイルを選択し(複数選択可)、上部リボンで [ホーム] > [一括タスク] > [一括翻訳] を選択した後 [次へ] をクリックし、[設定] ページの左ペインで [言語ペア] > [すべての言語ペア] > [一括処理] > [一括翻訳] を選択して、右側にある [一括翻訳の設定] の下の [一致率の最小値] を99~70%の間に設定してから [完了] をクリックします。
【upLIFTはこんな場合に便利】
上記の機能が理解できたところで、具体的にどのような場面で役立つかを見ていきましょう。
① 1文が長くマッチ率が低い場合
翻訳中に分節内の一部を見て「あ、前にもここは訳したことがある」と思っても、分節全体では翻訳メモリに一致しないことってありますよね? 例えば特許明細書や契約書など1文が長い文書はマッチ候補が少なくなりがちです。30%までマッチを表示するよう一致率の設定を下げている方もいるのではないでしょうか。
フラグメント一致は、長い原文分節であってもその中の部分ごとに翻訳メモリを検索をしてくれますのでマッチを拾いやすくなります。
以下の例では、各分節の原文が長いため分節全体のマッチはありませんが、下線付きの水色でハイライトされた訳文側のフレーズについては部分的にマッチする過去訳を翻訳メモリから(あるいは用語ベースに登録された訳語や機械翻訳から)流用可能であることを示しています。

② 訳語検索(コンコーダンス検索)をよく使用する方
Tradosには文の一部を任意で選択し翻訳メモリの中身を手動で検索する機能があります。
例えば以下は、手動で原文内の「アクセスキー」を選択してF3キーを押して訳語検索(コンコーダンス検索)を行っている例です。翻訳メモリの中から原文に「アクセスキー」を含む分節が [訳語検索] ウィンドウに表示されています。

フラグメント一致はこの操作を自動で行い候補を表示してくれるイメージです。便利でしょ?
よく訳語検索を使用する方は必見です!
また手動で行う訳語検索は訳文側の該当部分はハイライトされませんが、フラグメント一致は訳文の該当部分もハイライトをして表示できます。
③ 用語ベースを使用していない場合
フラグメント一致を使用することで、製品名や固有名詞などの用語がフラグメントとして表示され翻訳メモリ内の用語を一貫して使用していくことができます。
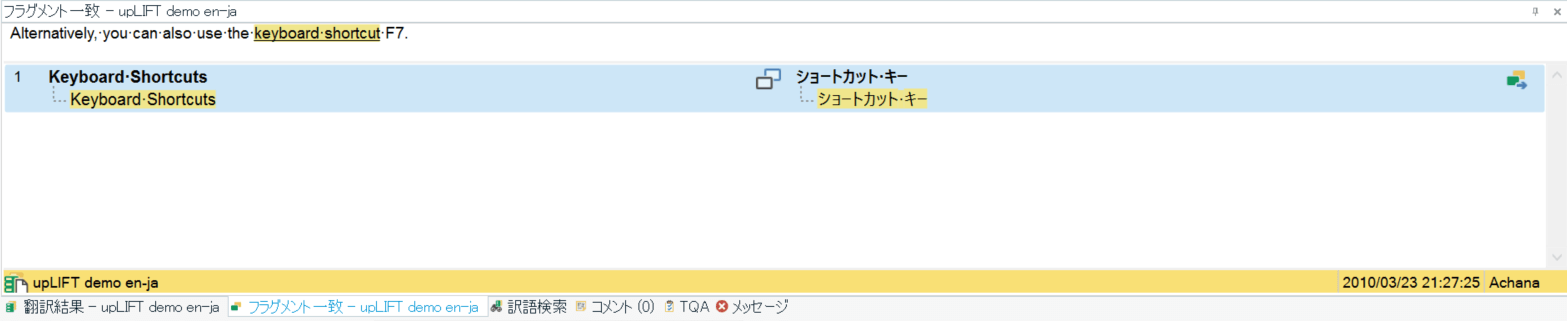
以下の例は、用語ベースを使用していないという想定で6分節目にフラグメント一致が見つかったケースです。翻訳メモリに登録されている分節では「keyboard shortcut」が「ショートカット キー」に訳されていますね。ここでもしフラグメント一致を使用しないと、誤って「キーボード ショートカット」と訳を入れても気づくことができず、表現がバラつく可能性がありますよね。
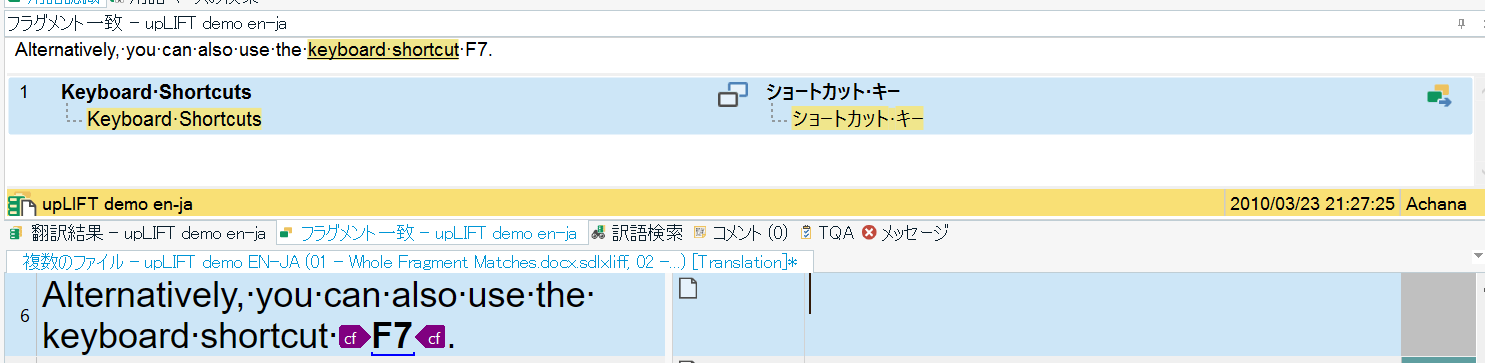
このようにフラグメントを活用することで翻訳メモリ内での用語を統一することもできます。
(用語ベースを使用していれば、登録用語を優先して使うのが通常です)
④ 用語や表現が変更された場合
例えば「製品A」という名前の製品が「製品B」に変更されたとします。
今後翻訳をする際、翻訳メモリからは「製品A」が含まれる分節がヒットしてきますが、毎回「製品A」を「製品B」へは手動で修正するのは面倒ですよね。このような作業は、塵も積もって大きな時間のロスになってしまいます。
あいまい一致の自動修正を使用すれば、「製品A」が「製品B」に自動で修正された状態で候補が表示されますので、修正時間を削減することができます。
【フラグメント一致を検索する語句の長さ(語数)を変更するには】
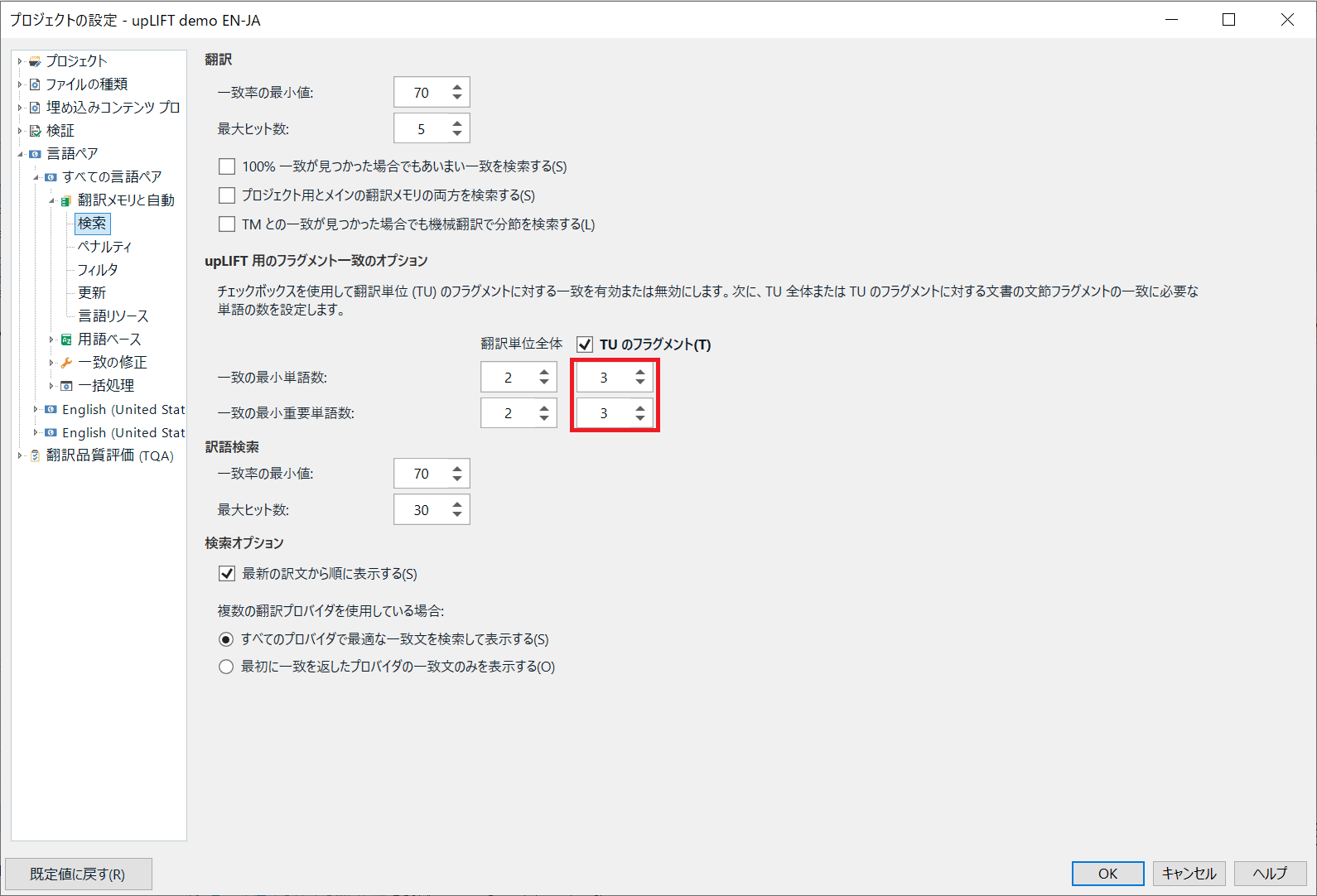
[プロジェクトの設定] > [言語ペア] > [すべての言語ペア] > [翻訳メモリと自動翻訳] > [検索] で [TUのフラグメント] がオンになっていることを確認し、その下の最小単語数を設定して下さい。
既定では3語に設定されていますが、フラグメント一致の候補が少ない場合は2語に変更してみることをお勧めします(※1語に設定をすると全単語を検索してしまうため、2語以上をお勧めします)。
反対に、候補が多すぎる場合には4語以上に調整してみることをお勧めします。
【フラグメント一致やあいまい一致の自動修正が思ったより働かない場合は】
upLIFTによる翻訳メモリの過去訳を利用したフラグメント一致やあいまい一致の自動修正は、翻訳メモリ内の翻訳単位から「翻訳モデル」と呼ばれるものを自動的に作成し、翻訳モデルに抽出された原文および訳文の語句グループを相互に対応付ける(整合する)ことにより実現されます。
一度に大量の翻訳単位が翻訳メモリに書き込まれると、この翻訳モデルや翻訳単位の整合が未完了の状態でupLIFTを実行することになるため、思ったよりもupLIFTが働かないといった場合があります(たとえば、A=Bという語句のペアを含む翻訳単位をつい先日、翻訳メモリに大量に登録したのに、フラグメント一致としてA=Bが表示されないといったケースです)。
このような場合は、[プロジェクトの設定] > [言語ペア] > [すべての言語ペア] > [翻訳メモリと自動翻訳] で(翻訳メモリ名の左にあるチェックボックスは選択せずに)翻訳メモリの名前の上をクリックし、その上の [設定] ボタン(歯車のアイコンの付いたボタン)をクリックします。
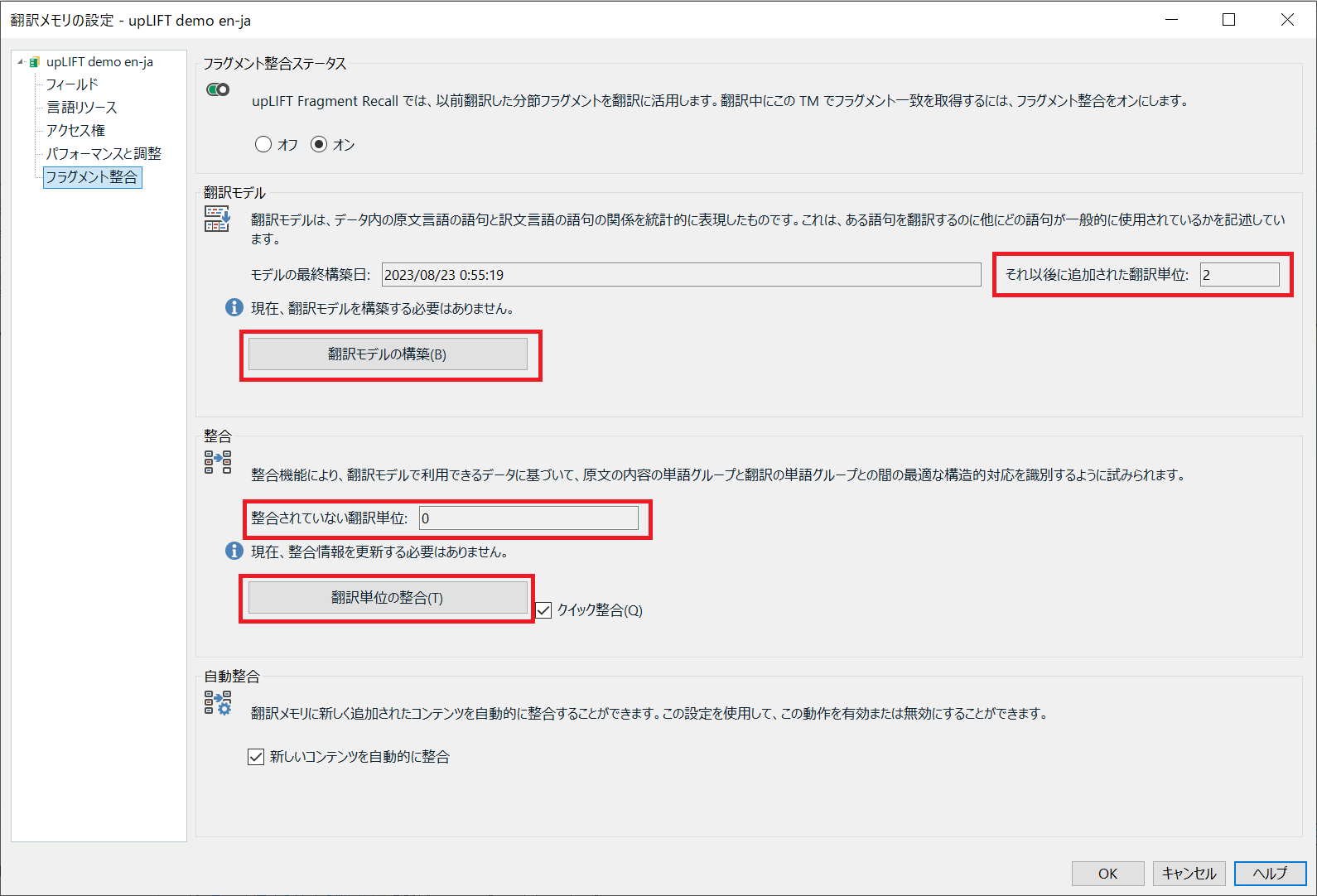
次に、[翻訳メモリの設定] ダイアログボックスの左ペインで [フラグメント整合] を選択し、右側にある [翻訳モデル] セクションと [整合] セクションの下で、[それ以後に追加された翻訳単位] および [整合されていない翻訳単位] の数値をそれぞれ確認します。
これらの数値が高く、その下に翻訳モデルの構築および整合が必要というメッセージが表示されている場合は、必要に応じて [翻訳モデルの構築] ボタンおよび [翻訳単位の整合] ボタンをそれぞれクリックします。
これにより、upLIFTが期待どおりに働くようになる場合がありますので、こちらのステータス情報もときどきご確認ください。
■Trados Studioの30日間無料トライアル■
■お問い合わせ■
製品に関するご質問・お問い合わせはコチラまでお気軽にご連絡下さい。